您现在的位置是:主页 > pg电子娱乐 >
没有演讲者的时间到了吗?曼巴(Mamba)的作者发
发布时间:2025-07-14 12:52编辑:365bet网址浏览(143)
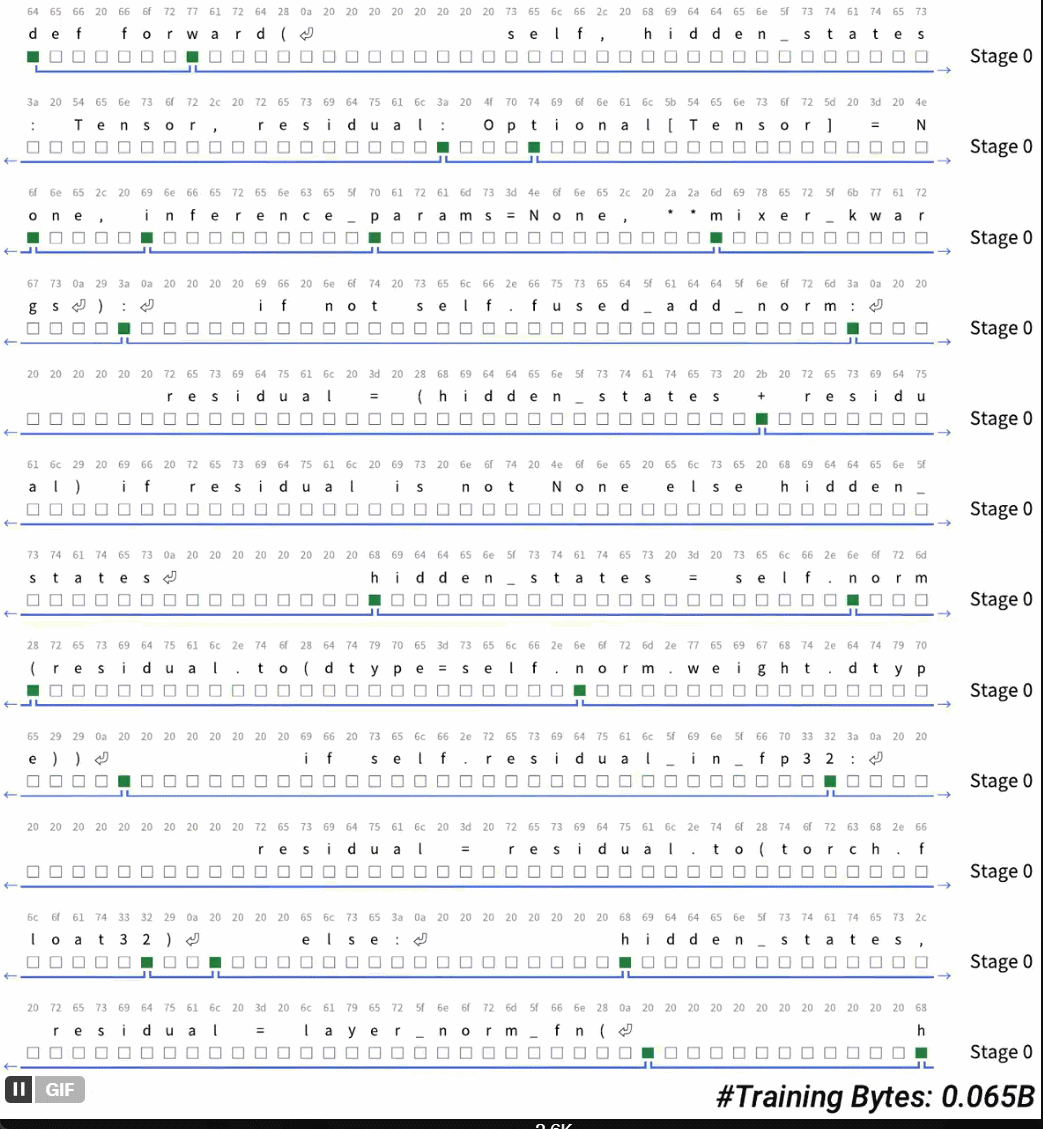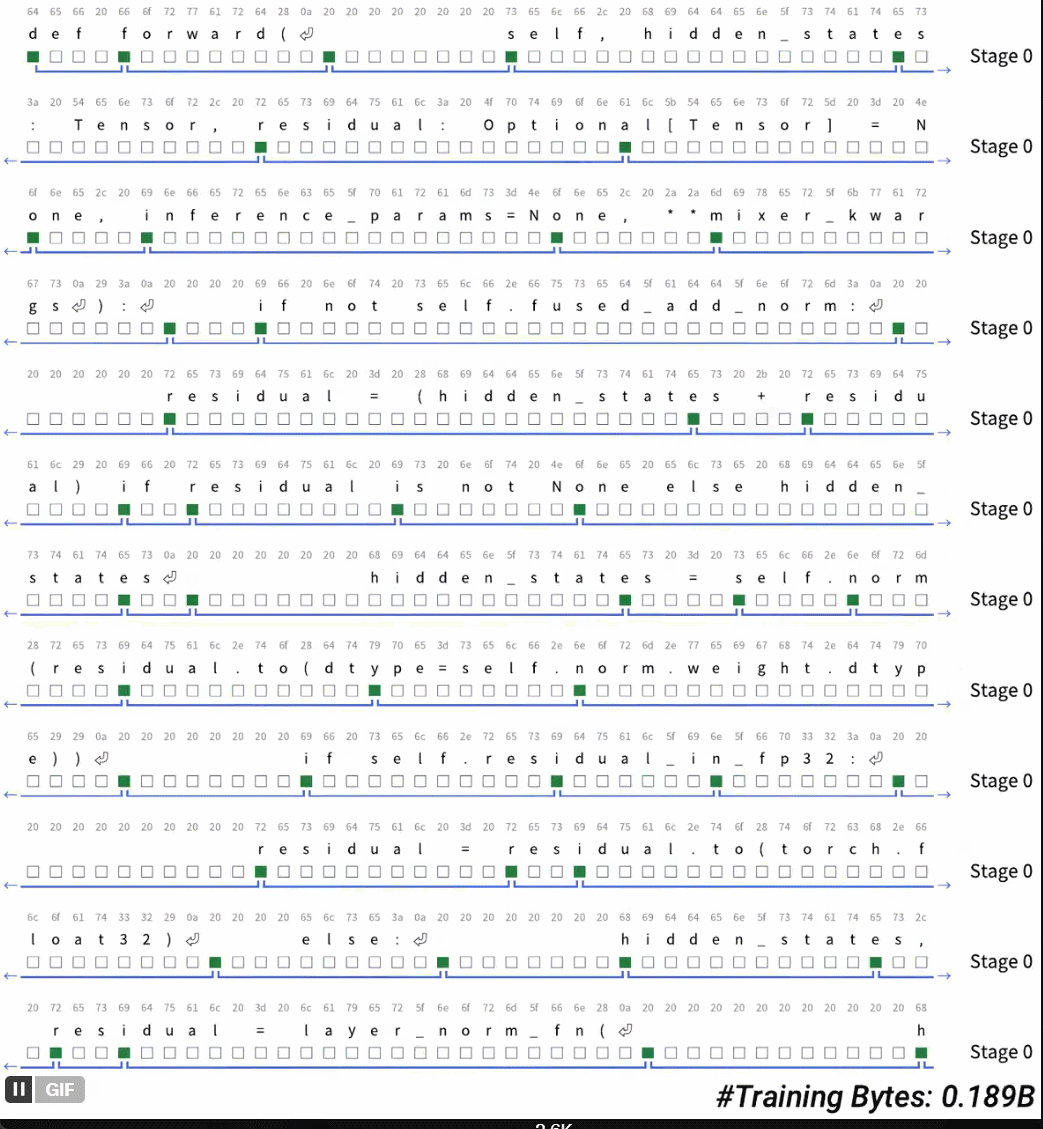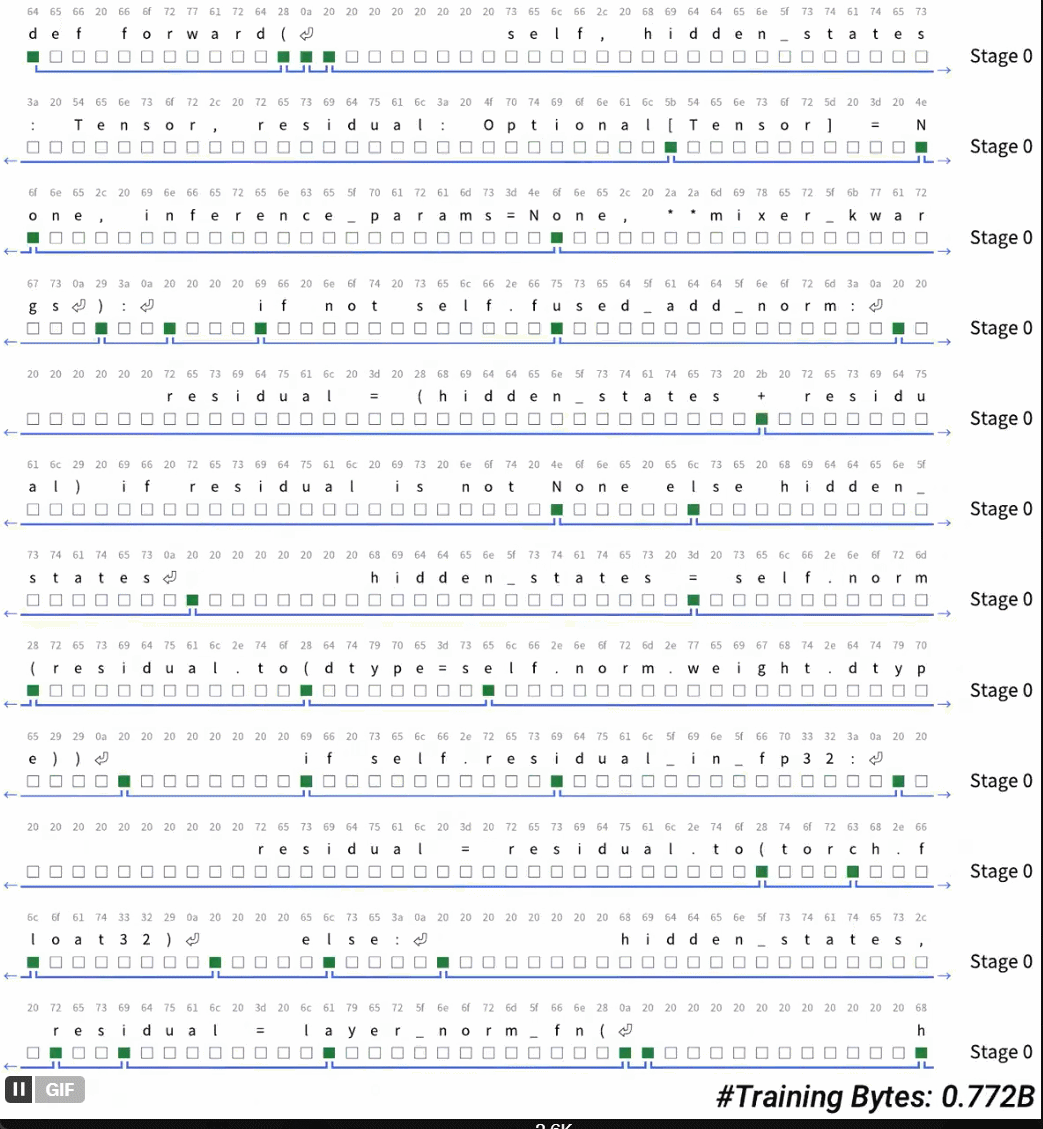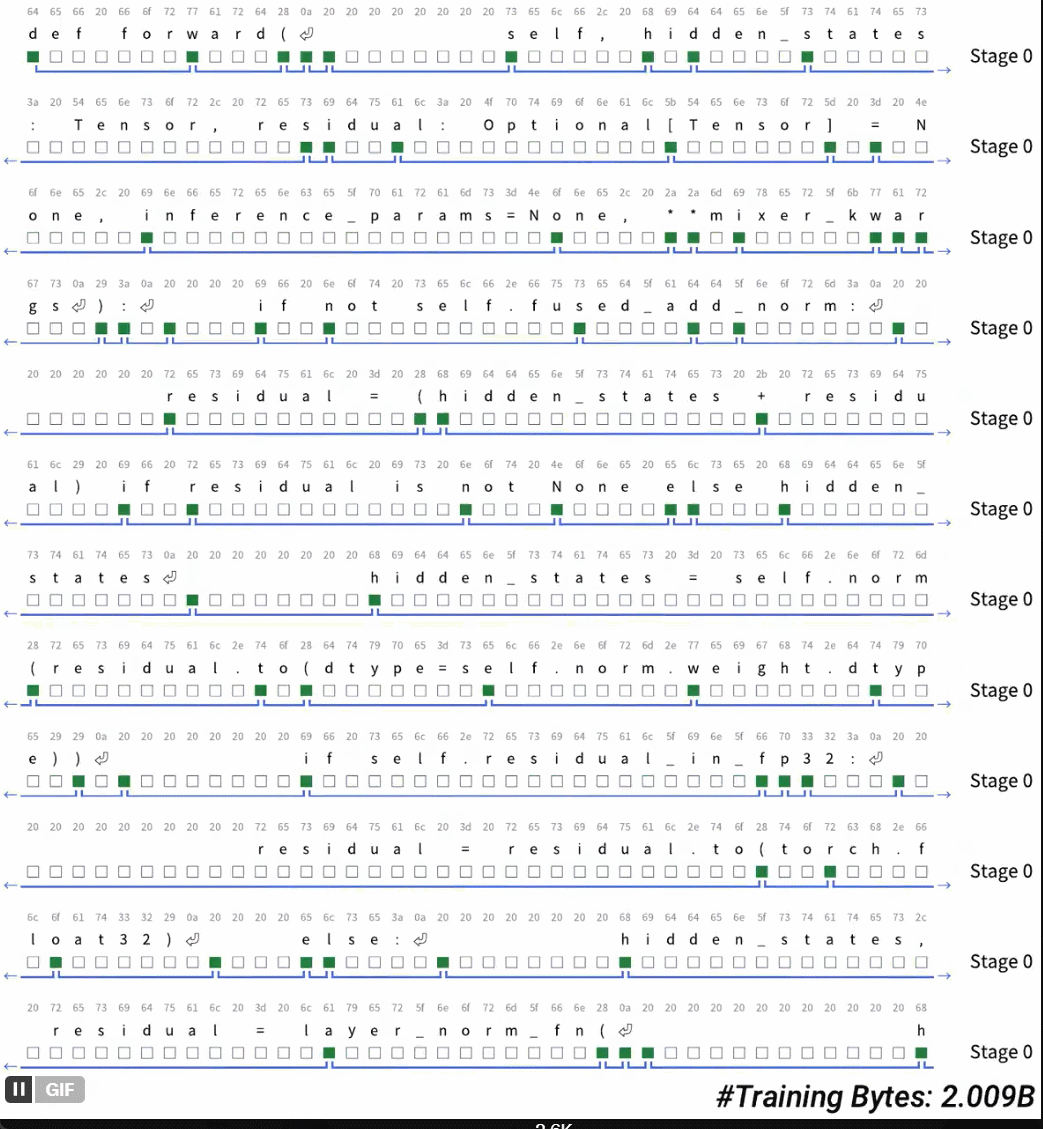 令牌化一直是执行真实端到 - 末端语言模型的最后障碍。您终于消除了令牌化吗?答案是:可能性是无限的。最近,曼巴(Mamba)的一位作者艾伯特·瓜(Albert Gu)发表了一项新研究。 H-NET分层网络提出了他的文档“端到头的层次序列建模的动态片段”。这用模型中的动态碎片过程取代了令牌化,从而发现并自动操纵重要的数据单位。 “这项研究表明,Tokensor正在离开现场,并且智能字节正在进行中。也许有实时的时间没有训练令牌:可能性是无限的。”在此阶段,令牌化仍然是语言模型和其他顺序数据的组成部分,因为它可以压缩和缩短序列。但是,象征化的hasmany不便,例如使用复杂语言时的解释性和性能降解(这样)作为中国,代码,DNA序列)。迄今为止,在计算预算重合时,基于对话的终点 - 末端对话模型都超过了语言模型的性能。最近,一些研究已经开始努力打破自我回归序列模型的令牌化的限制。在这种情况下,来自CMU等机构的研究人员Cartecia AI提出了一系列新技术,以通过动态阻止机制来执行内容的自适应分割策略,以与模型的其他部分合作学习。将这种机制集成到显式分层网络(H-NET)之后,可以完全从极端到结尾完全唯一的东西代替“ LM tokenized的爆炸”的最初隐式分层过程。在平等的计算机资源和数据量条件下,仅使用单个级别字节的层次结构模型,它们比trans racs单词模型ba更好地工作在BPE令牌上。通过多级分层迭代模型对不同水平的抽象建模将导致模型性能。-春季将进一步改善。这不仅改善了数据量表的效果,而且还基于代币的跨性别模型的效果,比量表大两倍。在英语前,H-NET可以在角色层面上大大提高鲁棒性,并使您在不明确监督启发式规则和一般过程的情况下,可以在定性地学习重要的分裂策略。最后,令牌化的启发式方法(在中国测序,语言和无礼的有效性,例如代码,DNA)中,H-NET过程比令牌化的优势更扩展得更多(数据效率几乎是基线的四倍),这表明真正的端到端模型的潜力可以更好地学习原始数据和可扩展原始数据的能力。纸张地址:https://arxiv.org/pdf/2507.079555v1最终序列NG模型没有令牌化,该文档提出了一个从端到极端(H-NET)的层次网络,该网络通过迭代动态过程和数据依赖性(DC,DC,Dynam)通过迭代动态过程和数据来压缩原始数据(见图1)。在保持与令牌化过程相同的效率的同时,H-NET可以通过识别内容和分割的识别,从而显着提高建模功能,并取决于从数据中汲取的上下文。 H-NET分层处理使用层次结构,SU工作流程分为三个步骤。精细处理:首先,使用小型编码器网络处理原始数据(字节/字符等)。压缩抽象:在压缩样品的压缩和还原样品后,它被输送到主要网络(可以成为大脑的核心)进行处理。输出修复:最后,随后并通过解码器恢复到原始精度。这种设计形成了自然认知层。外层捕获有序模式,而内层则处理抽象概念。重要的是要注意,主网络包含大多数参数,并且可以适用于标准体系结构,例如变形金刚和状态空间的模型(SSM)。动态H-ntexiste的核心中的主要网络和编码器/解码器网络在工作之间动态碎片机制(DC),您将在其中学习如何使用标准的可区分优化方法来分割数据。 DC由两种新的补充技术组成。 (i)通过相似性得分预测相邻元素之间限制的路由模块。 (ii)使用路由器输出插值来通过降低不确定限制的影响来大大提高学习能力的软化模块。通过将这些技术与新的辅助损失功能相结合并利用基于梯度的现代离散选择学习技术,DC可以学习H-NET如何组合完全以极端方式散布数据。信号传播本文档还提出了几种架构和训练技术,以提高末端至末端优化过程的稳定性和可扩展性。这些技术包括:(i)交互式子网中信号的投影和标准化外行。 (ii)根据每一层的尺寸和有效批次的大小调整优化参数。通常,H-NET与中继网络合作学习优化的分割策略,并根据上下文信息在重要的数据块中动态压缩输入向量。 H-NET代表第一个端到端语言模型,Tokensor Free。通过动态碎片阶段,字节级别的H网络提供了功能强大的BPE令牌,并具有10亿个参数。 Sformer有足够的混乱和后续的表现。从经验上讲,动态碎片模块自然压缩数据为similAR对BPE的thall talk talle(每个块4.5-5个字节),并在没有外部或启发式监督的情况下学习了质量上的显着限制。在实验和结果中,本文档中使用的原理语言模型的体系结构如下:例如,Mambabyte是一种使用纯Mamba-2层的各向同性模型。训练曲线。图3通过训练大型模型尺度和XL模型量表显示了验证BPB指标。图3显示了整个训练过程中的较大XL量表。对模型的BPB指标进行验证。在本文中,我们注意到在大型文章中,所有各向同性模型都远低于层次绩效模型。在这些模型中,山babyte明显优于ramabyte。 SpaceByte明显低于SpaceByte ++,此结果验证了使用Mamba在外部网络中使用Mamba的有效性。 SpaceByte ++也比H-NET(空间)差,表明改进了本文档中提出的信号传播技术。 H -NET(Space)是一个非常强大的模型器,可提供与BPE变形金刚的可比性能,从而研究了与数据相关的阻止策略的效果以及精心设计的分层体系结构的影响。表2显示了下游多个参考点中不同模型样品的准确性。 SpaceByte ++,H-NET(Space)和H-N-NET(一个阶段)的工作方式类似于大规模BPE变压器,在XL尺度上略超过BPE变压器。表3评估了Hellaswag模型的鲁棒性。与所有参考模型相比,H-NET(两个阶段)可显着提高鲁棒性。图4显示了H-NET(第一阶段)和H-NET(第二阶段)动态绘制限制的可视化。这些可视化提供了一些有关模型如何确定限制的重要想法。即使使用令牌3个代理,该文档也发现H-NET(两个阶段)Hasbetter可伸缩性比中文可伸缩性BPE变压器和代码和H-NET(空格)(图5),并在阻尼阶段后达到较低的压缩率(表4)。先前的研究表明,对于DNA序列建模而言,SSM不仅仅是TR,从而改善了ANSFORMER的性能。这也经过实验证明(表5):即使替换为主要网络,Mamba-2仍然存在SSM优势。实际上,在直接在稳定的训练阶段进行混淆曲线(图6)时,本文档显示在本文档中,H-NET模型仅是数据量的3.6倍。我们发现我们可以与Leme取得类似的性能。该发现适合选择两个主要的网络体系结构。最后,艾伯特(Albert)还写了一些关于现场故事的出色博客文章,以及有关H-NET的激动人心的想法。这些可以去阅读。博客地址:https://goombalab.github.io/blog/2025/hnet-past/lease请参阅原始文档以获取更多信息。
令牌化一直是执行真实端到 - 末端语言模型的最后障碍。您终于消除了令牌化吗?答案是:可能性是无限的。最近,曼巴(Mamba)的一位作者艾伯特·瓜(Albert Gu)发表了一项新研究。 H-NET分层网络提出了他的文档“端到头的层次序列建模的动态片段”。这用模型中的动态碎片过程取代了令牌化,从而发现并自动操纵重要的数据单位。 “这项研究表明,Tokensor正在离开现场,并且智能字节正在进行中。也许有实时的时间没有训练令牌:可能性是无限的。”在此阶段,令牌化仍然是语言模型和其他顺序数据的组成部分,因为它可以压缩和缩短序列。但是,象征化的hasmany不便,例如使用复杂语言时的解释性和性能降解(这样)作为中国,代码,DNA序列)。迄今为止,在计算预算重合时,基于对话的终点 - 末端对话模型都超过了语言模型的性能。最近,一些研究已经开始努力打破自我回归序列模型的令牌化的限制。在这种情况下,来自CMU等机构的研究人员Cartecia AI提出了一系列新技术,以通过动态阻止机制来执行内容的自适应分割策略,以与模型的其他部分合作学习。将这种机制集成到显式分层网络(H-NET)之后,可以完全从极端到结尾完全唯一的东西代替“ LM tokenized的爆炸”的最初隐式分层过程。在平等的计算机资源和数据量条件下,仅使用单个级别字节的层次结构模型,它们比trans racs单词模型ba更好地工作在BPE令牌上。通过多级分层迭代模型对不同水平的抽象建模将导致模型性能。-春季将进一步改善。这不仅改善了数据量表的效果,而且还基于代币的跨性别模型的效果,比量表大两倍。在英语前,H-NET可以在角色层面上大大提高鲁棒性,并使您在不明确监督启发式规则和一般过程的情况下,可以在定性地学习重要的分裂策略。最后,令牌化的启发式方法(在中国测序,语言和无礼的有效性,例如代码,DNA)中,H-NET过程比令牌化的优势更扩展得更多(数据效率几乎是基线的四倍),这表明真正的端到端模型的潜力可以更好地学习原始数据和可扩展原始数据的能力。纸张地址:https://arxiv.org/pdf/2507.079555v1最终序列NG模型没有令牌化,该文档提出了一个从端到极端(H-NET)的层次网络,该网络通过迭代动态过程和数据依赖性(DC,DC,Dynam)通过迭代动态过程和数据来压缩原始数据(见图1)。在保持与令牌化过程相同的效率的同时,H-NET可以通过识别内容和分割的识别,从而显着提高建模功能,并取决于从数据中汲取的上下文。 H-NET分层处理使用层次结构,SU工作流程分为三个步骤。精细处理:首先,使用小型编码器网络处理原始数据(字节/字符等)。压缩抽象:在压缩样品的压缩和还原样品后,它被输送到主要网络(可以成为大脑的核心)进行处理。输出修复:最后,随后并通过解码器恢复到原始精度。这种设计形成了自然认知层。外层捕获有序模式,而内层则处理抽象概念。重要的是要注意,主网络包含大多数参数,并且可以适用于标准体系结构,例如变形金刚和状态空间的模型(SSM)。动态H-ntexiste的核心中的主要网络和编码器/解码器网络在工作之间动态碎片机制(DC),您将在其中学习如何使用标准的可区分优化方法来分割数据。 DC由两种新的补充技术组成。 (i)通过相似性得分预测相邻元素之间限制的路由模块。 (ii)使用路由器输出插值来通过降低不确定限制的影响来大大提高学习能力的软化模块。通过将这些技术与新的辅助损失功能相结合并利用基于梯度的现代离散选择学习技术,DC可以学习H-NET如何组合完全以极端方式散布数据。信号传播本文档还提出了几种架构和训练技术,以提高末端至末端优化过程的稳定性和可扩展性。这些技术包括:(i)交互式子网中信号的投影和标准化外行。 (ii)根据每一层的尺寸和有效批次的大小调整优化参数。通常,H-NET与中继网络合作学习优化的分割策略,并根据上下文信息在重要的数据块中动态压缩输入向量。 H-NET代表第一个端到端语言模型,Tokensor Free。通过动态碎片阶段,字节级别的H网络提供了功能强大的BPE令牌,并具有10亿个参数。 Sformer有足够的混乱和后续的表现。从经验上讲,动态碎片模块自然压缩数据为similAR对BPE的thall talk talle(每个块4.5-5个字节),并在没有外部或启发式监督的情况下学习了质量上的显着限制。在实验和结果中,本文档中使用的原理语言模型的体系结构如下:例如,Mambabyte是一种使用纯Mamba-2层的各向同性模型。训练曲线。图3通过训练大型模型尺度和XL模型量表显示了验证BPB指标。图3显示了整个训练过程中的较大XL量表。对模型的BPB指标进行验证。在本文中,我们注意到在大型文章中,所有各向同性模型都远低于层次绩效模型。在这些模型中,山babyte明显优于ramabyte。 SpaceByte明显低于SpaceByte ++,此结果验证了使用Mamba在外部网络中使用Mamba的有效性。 SpaceByte ++也比H-NET(空间)差,表明改进了本文档中提出的信号传播技术。 H -NET(Space)是一个非常强大的模型器,可提供与BPE变形金刚的可比性能,从而研究了与数据相关的阻止策略的效果以及精心设计的分层体系结构的影响。表2显示了下游多个参考点中不同模型样品的准确性。 SpaceByte ++,H-NET(Space)和H-N-NET(一个阶段)的工作方式类似于大规模BPE变压器,在XL尺度上略超过BPE变压器。表3评估了Hellaswag模型的鲁棒性。与所有参考模型相比,H-NET(两个阶段)可显着提高鲁棒性。图4显示了H-NET(第一阶段)和H-NET(第二阶段)动态绘制限制的可视化。这些可视化提供了一些有关模型如何确定限制的重要想法。即使使用令牌3个代理,该文档也发现H-NET(两个阶段)Hasbetter可伸缩性比中文可伸缩性BPE变压器和代码和H-NET(空格)(图5),并在阻尼阶段后达到较低的压缩率(表4)。先前的研究表明,对于DNA序列建模而言,SSM不仅仅是TR,从而改善了ANSFORMER的性能。这也经过实验证明(表5):即使替换为主要网络,Mamba-2仍然存在SSM优势。实际上,在直接在稳定的训练阶段进行混淆曲线(图6)时,本文档显示在本文档中,H-NET模型仅是数据量的3.6倍。我们发现我们可以与Leme取得类似的性能。该发现适合选择两个主要的网络体系结构。最后,艾伯特(Albert)还写了一些关于现场故事的出色博客文章,以及有关H-NET的激动人心的想法。这些可以去阅读。博客地址:https://goombalab.github.io/blog/2025/hnet-past/lease请参阅原始文档以获取更多信息。
上一篇:超级融合32G 4800内存服务器税1,400元高频能源
下一篇:没有了